역전파
이 부분을 이해하기 전에, Deep Learning에 대한 전반적인 과정을 이해하는 것이 좋다.
앞부분에서는 cost 함수를 정의하고 이를 학습하는데 있어 gradient descent 방법을 활용했다.
그런데, 근본적인 NN의 한계는 XOR문제를 풀지 못한다는 점이었는데, 이를 해결하려면 2개 이상의 Layer가 필요했다.
그렇게 되면서 여러 Layer를 활용한 NN모델이 나오게 되었는데, 그렇다면, 이 여러 개의 Layer를 쌓은 NN모델은 어떻게 학습을 해야하는가? 그것이 바로 역전파이다.
우리는 결국, cost함수를 최소화하는데 있어서, w, x, b가 주는 각각의 영향력(미분값)을 알아내야 한다. 그리고 이 값들을 토대로 경사하강법을 수행해야 한다.
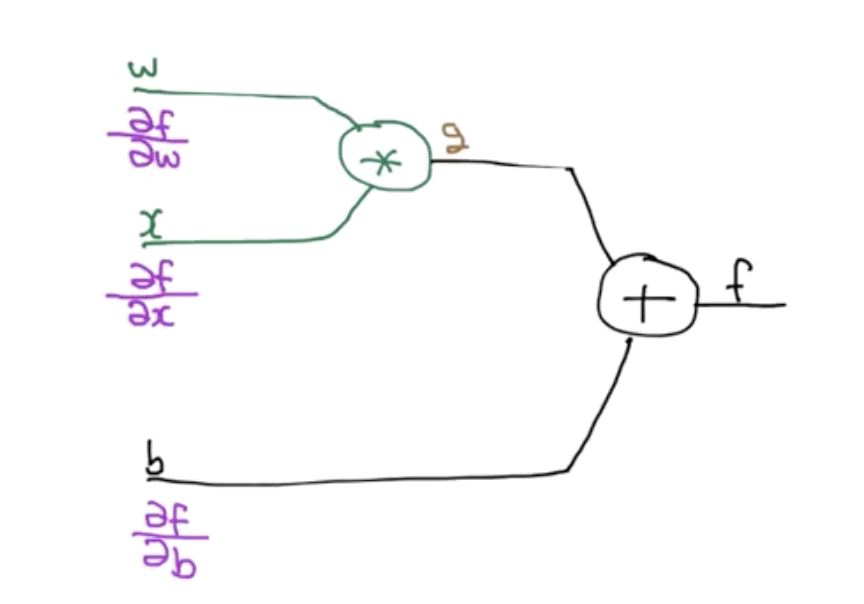
Chain rule
결국 왼쪽에 놓여있는 각 편미분값은 연쇄법칙으로 구해질 수 있다.
잘 보게되면, 사용되는 미분 값은 4개가 전부이다.
여기로 부터,
이 4개의 값이 조합되어 원하는 값을 얻을 수 있다.
각 변수 x, w, b는 초기에 정해진 값이 넣어지게 된다.