핵심 아이디어
Region Proposal도 Network안에 포함시키자!
Faster R-CNN의 핵심 아이디어는 Resion Proposal Network(이하 RPN)이다. 기존 Fast R-CNN구조를 계승하면서 selective search를 제거하고 RPN을 통해서 Roi를 계산한다. 이를 통해서 GPU를 통해 Roi를 계산할 수 있게 되었고, 이 RoI를 추출하는 것 역시 학습시켜 정확도를 높일 수 있다. 결과적으로 selective search가 2000개 RoI를 계산하는데 반해, 800개 정도로 더 높은 정확도를 가진다.
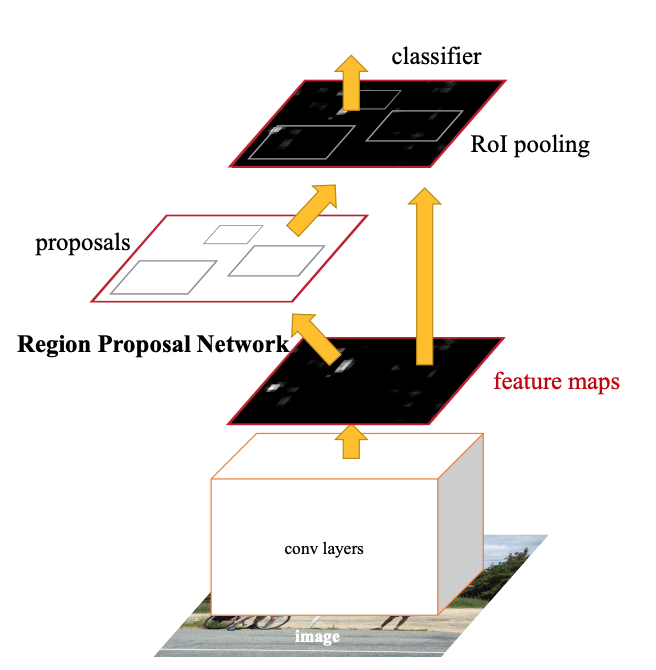
그림을 보면 알겠지만, feature map으로 부터 selective search를 거치치 않고 이를 RPN에 전달하여 계산을 진행한다. 여기서 얻은 RoI로 RoI Pooling을 진행한 다음 object detection을 진행한다.
Region Proposal Network
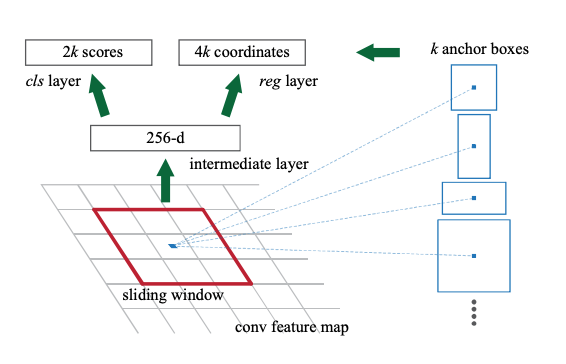
이 그림보다는 순차적으로 된 그림으로 이해하는 것이 쉽다.
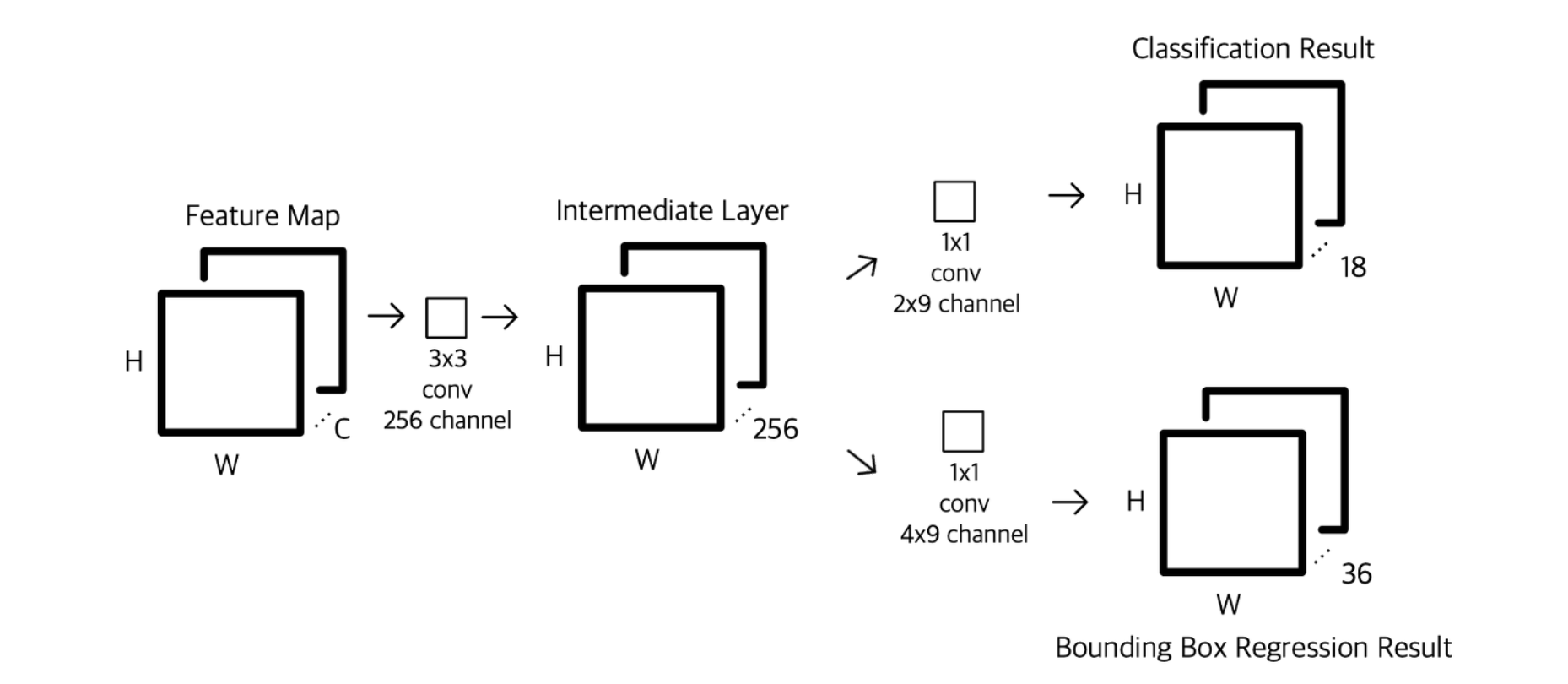
CNN을 통해 뽑아낸 feature map을 입력으로 받는다. 어떤 pretrained model을 사용할 지 모르므로 이를 HxWxC로 둔다.
feature map에 (3x3)x256 또는 (3x3)x512 conv 연산을 수행한다. 엄밀히 말하면 C와 256, 512는 같아야 한다. 일단 연산이 가능하다고 가정하자. 이 때, HxW가 보존될 수 있게 padding을 1로 설정한다.
전 과정에서 나온 feature map을 가지고 classification을 위한 확률값과, bounding box regression 값을 뽑아낸다. 이 과정에서 너무 많은 연산을 진행하게 되면 모델이 지나치게 무거워 진다. 저자들은 1 x 1 conv만을 수행하여 예측값을 뽑아내고자 하였다.
 먼저
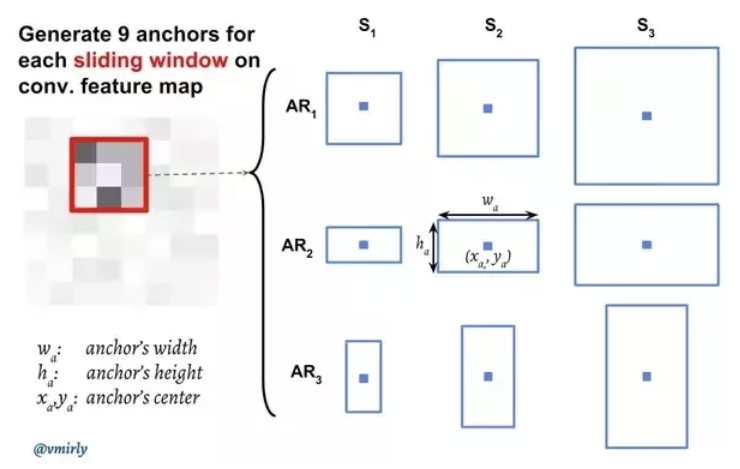
먼저 Classification의 경우, 더욱 가볍게 진행하기 위해 물체인지 아닌지를 구분하는 binary classification을 진행하고자 하였다. 하지만 이 문제는 bounding box와 엮어서 이를 생각해야 하는데, 저자들은 이 단계에서 Anchor라는 개념을 도입하여 이를 진행하였다. Anchor는 간단하게 사전에 정의해 둔 Box들이다. 총 9개를 사용하였다.
이 모든 내용을 정리하면, classification의 결과는 총 (HxW)의 각각의 위치에 제안된 Anchor(9개)에 대해 물체의 여부(2)를 나타내는 총 18개의 Node를 가져야 한다. 그러기 위해 (1x1)x(2x9)의 conv 연산을 진행하였다. 결과적으로 (HxW)x(2x9)의 Feature map이 나오고, 각각의 노드는 순서대로 (h, w) 위치에 있는 1번 anchor가 물체일 logit, (h, w) 위치에 있는 1번 anchor가 물체가 아닐 logit … 로 정의된다. 최종적으로 이를 확률 값으로 변경해주기 위해 적절히 reshape 해준 다음 Softmax를 적용한다.
두번째로 Bounding Box Regression을 진행한다. 같은 방법을 사용한다. 이번에는 9개 anchor에 대해 총 4개의 좌표를 수정하기 위한 조절값을 예측해야 하므로 (H W)x(4x9)의 결과를 얻어야 한다. 이번에는 regression이기 때문에 그대로 결과값으로 사용하면 된다.
앞선 과정은 순차적으로 진행된다. 즉, classification을 먼저 진행하고, 이 결과를 기반으로 물체일 확률을 sorting한다. 이 중 높은 순으로 K개의 anchor를 후보군으로 선정한다. 이 후보군에 각각 bounding Box Regression을 진행한다. 마지막으로 Non-Maximum-Suppression을 적용하고, 이것을 기반으로 RoI를 제안한다.
이러한 방법을 통해서 RoI를 제안하는 Network를 만들었다. 이 후 과정은, 이렇게 만들어진 RoI를 첫번째 Feature map (HxWxC) 에 투영하는 과정을 거친다. 이 부분은 Fast R-CNN 구조와 같다.
RPN’s Loss function
RPN은 앞서서 Classification과 Bouding Box Regression을 수행했다. 로스 펑션은 이 두 가지 테스크에서 얻은 로스를 엮은 형태를 취하고 있다.
여기서 i는 하나의 anchor를 말한다. 는 classification을 통해서 얻은 해당 anchor가 object일 확률을 의미한다. 는 bounding box regression을 통해서 얻은 박스 조정 값 벡터를 의미한다. *이 붙은 변수는 ground truth label에 해당된다.
classification은 binary cross entropy, regression은 smooth L1 loss를 사용한다.
주목해야 할 점은 각각 와 를 가진다는 점이다. 는 minibatch 사이즈이며 논문에서는 256입니다. 는 엥커 개수에 해당하며 약 2400개 (256 x 9)에 해당한다. 실제 실험을 진행했을 떄 이부분이 큰 부분을 담당하지는 않는다고 말한다. 는 Classifiaction Loss와 Regression Loss 사이에 가중치를 조절해주는 부분인데 논문에서는 10으로 설정되어 있어, 사실상 두 로스는 동일하게 가중치가 매겨진다. 이후는 Fast R-CNN 구조와 같다. 이제 남은 것은 어떻게 이 두 네트워크를 학습시키느냐에 대한 것이다.
Training Method
하지만 전체 모델을 한번에 학습시키기란 매우 어려운 작업이다. RPN이 제대로 RoI를 계산해내지 못하는데 뒷 단의 Classification 레이어가 학습될 리가 없다. 여기서 저자들은 4단계에 걸쳐서 모델을 번갈아서 학습시키는 Alternating Training 기법을 취한다. 말이 어렵지 그냥 따로 하고 지지고 볶으면서 학습시킨거다.
ImageNet pretrained모델을 불러온 다음,RPN을 학습시킨다.- 1 단계에서 학습시킨
RPN에서 기본 CNN을 제외한Region Proposal 레이어만 가져온다. 이를 활용하여 Fast RCNN을 학습시킨다. 이 때 , 처음 피쳐맵을 추출하는 CNN까지fine tune시킨다. - 앞서 학습시킨
Fast RCNN과RPN을 불러온 다음, 다른 웨이트들은 고정하고RPN에 해당하는 레이어들만fine tune시킨다. 여기서부터RPN과Fast RCNN이 컨볼루션 웨이트를 공유하게 된다. - 마지막으로 공유하는 CNN과
RPN은 고정시킨 채,Fast R-CNN에 해당하는 레이어만fine tune시킨다.
의의
region proposal을 한번에 수행
한계
- 여전히
real time이라고 하기에는 무리가 있음 - 여전히 학습과정이 복잡하고 2step 임