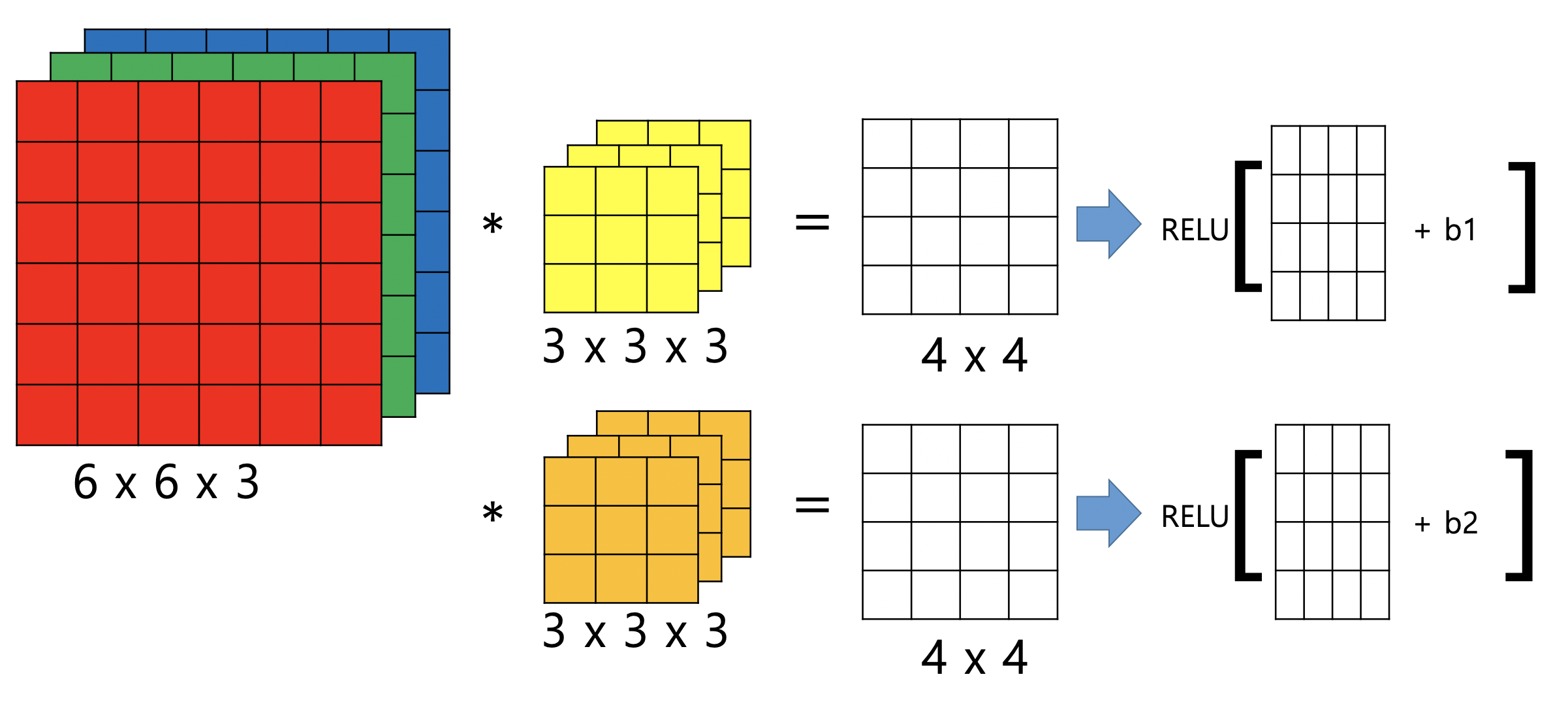
Example of a Layer
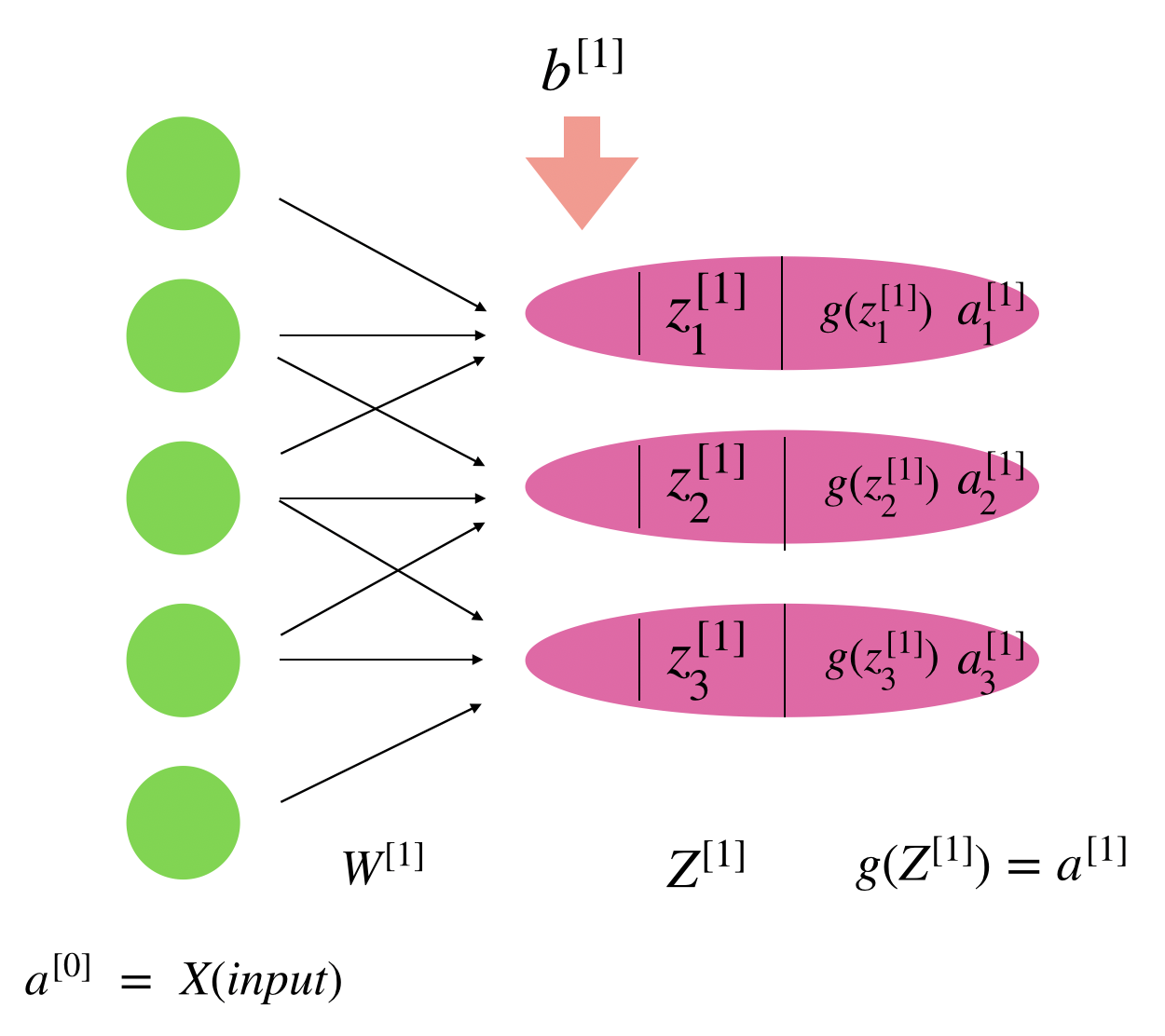
- 이제 원래 배웠던 신경망의 노드에서 하는 활동으로 돌아오자.
- 결국 이 필터는 가중치들의 모임이고,
- 원래 데이터에서 이 가중치를 곱한다음에 더하는 행위는 한 노드에 이 데이터들이 들어가는 것이다.
- 하나의 노드에 연결된 많은 노드들에 가중치를 곱하고 다 더한다음에 우리는 뭘했었지?
- Activation Function에다가 이 값을 넣고 출력값을 얻었다.
- 이걸 시각화 해보면!
- 이렇게 된다.
- 원래 각각의 노드에 대해 Bias 항이 생긴다고 알았던 것과 달리
- 구현을 위해서는 출력에 대해 같은 Bias를 더해주는 것이 효율적이다.
- 이 연산의 결과로 우리는 4 x 4 x 2 를 얻을 수 있다.
- 그리고 이 것이 Convolution network의 한 Layer가 된다.
- 이걸 행렬의 형태로 정리해 보면,
그림으로 다시한번 보자.
- 결국 완전 연결과 달라진 것은 몇개 단위로 연결을 하느냐! 만 달라졌다.
Example
- 만약 3 x 3 x 3 필터가 10개 있을 때, 파라미텨는 몇개일까?
- 1개의 필터에 들어가는 변수가 27개 이고, 이 필터에 적용되는 Bias는 1개이므로
- 1개의 필터당 생기는 변수는 28개이다.
- 이게 10개가 있으므로 우리가 조정해줘야하는 파라미터는 총 280개 이다.
- 이것이 유용한 이유는, 완전 연결망에서 우리는 노드가 모두 연결되어 있기 때문에,
- 입력 변수가 많게 되면 파라미터 수는 기하 급수적으로 증가했다.
- 그렇기 때문에 이 파라미터들의 최적값을 찾기가 어려웠는데,
- 이제 노드에 파라미터를 적용할 때, 제한된 범위의 파라미터만 적용하게 되므로,
- 즉 필터의 크기로 제한하게 되므로, 이제는 입력값이 커지더라도 파라미터의 개수가 증가하여 생기는
- 문제를 해결할 수 있다.
- 즉 위 문제에서 입력이 1000 x 1000 픽셀의 이미지가 들어오더라도 여전히 내가 검출하고 싶은
- 특성 필터는 10개 이므로, 280개의 파라미터만 조정하여 속성을 검출할 수 있다!
Notation
l 번째 Convolution Layer에 있을때
<Input>\\ n_H^{\[l-1\]} \times n_W^{\[l-1\]}\times n_C^{\[l-1\]}\\ Because ;it ;is;value;of;the activation;of;previous;layer \\ we; use; l-1\\ And,\\ Input ;is;equal;to;a^{\[l-1\]}\\ So,\\ a^{\[l-1\]};=;n_H^{\[l-1\]} \times n_W^{\[l-1\]}\times n_C^{\[l-1\]}- a는 이전 계층의 노드들을 통칭해서 얘기한다.
- 각 필터의 채널수와, 전체 채널 개수를 잘 보자.
- 가중치 총 개수와 필터와의 관계도 잘 보자.
- 여기서 주목해야 하는 것은 각 필터의 채널은 이전 활성 input의 채널과 같아야 한다는 점.
- 그리고 필터의 개수가 output의 채널 개수를 결정한다는 점이다!
Example of Simple Convolutional Network
Construction
전체적인 구조는 다음과 같다.
graph LR
A[X-input] --> |Conv1|B[Layer 1]
B --> |Conv2|C[Layer 2]
C --> |FullyConct|D[Layer 3]
D --> |SoftMax|E[Prediction]
결국 Convolution Network에서 우리가 중점적으로 손을 봐야하는 것은, 이 과정을 수행하는 데 있어 어떤 Hyperparameter를 쓰느냐이다.
이것이 궁극적으로 구조를 변화시키기 때문이다.
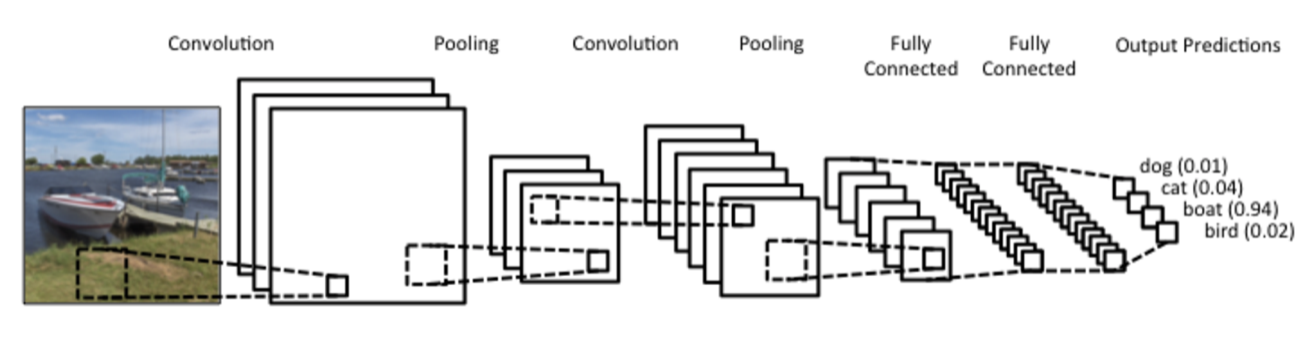
또한 이렇게 처음 이미지는 RGB의 3개의 채널만 가지고 있지만, Layer가 증가하면서 Channel 수가 증가하는 양상을 보인다.
직관적으로는 처음에는 간단한 하위특성(수직선, 수평선) 등만 탐색하다가 이것들의 조합으로 만들어지는 수많은 특성들이 있게되므로 점점 많은 필터(특성)를 사용하는 듯하다.
What is Parameter, Hyperparameter
파라미터는 가중치를 얘기한다. 그리고 하이퍼파라미터는 필터의 크기, 스트라이드, 패딩과 같은 값을 의미한다.
즉, 파라미터란, 우리가 궁극적으로 구하고 싶은 변수를 의미하고, 하이퍼 파라미터란 그 과정속에서 필요한 변수들을 의미한다.
하이퍼 파라미터의 예시로는 Gradient Deacent 의 learning rate가 있겠다.