Numpy.loadtxt()
단, csv 파일의 모든 값이 같은 자료형이어야 한다.
# Lab 4 Multi-variable linear regression
import tensorflow as tf
import numpy as np
tf.set_random_seed(777) # for reproducibility
xy = np.loadtxt('data-01-test-score.csv', delimiter=',', dtype=np.float32)
x_data = xy[:, 0:-1]
y_data = xy[:, [-1]]-
Slicing을 모르겠어요!
[3:5] => 3이상 5미만 (3, 4) [:] => 전체 리스트 값 출력 (0, 1, 2, 3, 4, 5) [:-1] => 끝에서 하나 뺴고 다 가져와 (0, 1, 2, 3, 4) [2:4] = [8,9] => 2이상, 4미만 자리에 8,9를 넣어줘 (1, 8, 9, 4, 5)
데이터 불러오기 코드
# Lab 4 Multi-variable linear regression
import tensorflow as tf
import numpy as np
tf.set_random_seed(777) # for reproducibility
xy = np.loadtxt('data-01-test-score.csv', delimiter=',', dtype=np.float32)
x_data = xy[:, 0:-1]
y_data = xy[:, [-1]]
# Make sure the shape and data are OK
print(x_data, "\nx_data shape:", x_data.shape)
print(y_data, "\ny_data shape:", y_data.shape)[[ 73. 80. 75.]
[ 93. 88. 93.]
...
[ 76. 83. 71.]
[ 96. 93. 95.]]
x_data shape: (25, 3)
[[152.]
[185.]
...
[149.]
[192.]]
y_data shape: (25, 1)Placeholder에 값 넣어서 print해보기
# Lab 4 Multi-variable linear regression
import tensorflow as tf
import numpy as np
tf.set_random_seed(777) # for reproducibility
xy = np.loadtxt('data-01-test-score.csv', delimiter=',', dtype=np.float32)
x_data = xy[:, 0:-1]
y_data = xy[:, [-1]]
# Make sure the shape and data are OK
print(x_data, "\nx_data shape:", x_data.shape)
print(y_data, "\ny_data shape:", y_data.shape)
# data output
'''
[[ 73. 80. 75.]
[ 93. 88. 93.]
...
[ 76. 83. 71.]
[ 96. 93. 95.]]
x_data shape: (25, 3)
[[152.]
[185.]
...
[149.]
[192.]]
y_data shape: (25, 1)
'''
# placeholders for a tensor that will be always fed.
X = tf.placeholder(tf.float32, shape=[None, 3])
Y = tf.placeholder(tf.float32, shape=[None, 1])
W = tf.Variable(tf.random_normal([3, 1]), name='weight')
b = tf.Variable(tf.random_normal([1]), name='bias')
# Hypothesis
hypothesis = tf.matmul(X, W) + b
# Simplified cost/loss function
cost = tf.reduce_mean(tf.square(hypothesis - Y))
# Minimize
optimizer = tf.train.GradientDescentOptimizer(learning_rate=1e-5)
train = optimizer.minimize(cost)
# Launch the graph in a session.
sess = tf.Session()
# Initializes global variables in the graph.
sess.run(tf.global_variables_initializer())
for step in range(2001):
cost_val, hy_val, _ = sess.run([cost, hypothesis, train],
feed_dict={X: x_data, Y: y_data})
if step % 10 == 0:
print(step, "Cost:", cost_val, "\nPrediction:\n", hy_val)
# train output
'''
0 Cost: 21027.0
Prediction:
[[22.048063 ]
[21.619772 ]
...
[31.36112 ]
[24.986364 ]]
10 Cost: 95.976326
Prediction:
[[157.11063 ]
[183.99283 ]
...
[167.48862 ]
[193.25117 ]]
1990 Cost: 24.863274
Prediction:
[[154.4393 ]
[185.5584 ]
...
[158.27443 ]
[192.79778 ]]
2000 Cost: 24.722485
Prediction:
[[154.42894 ]
[185.5586 ]
...
[158.24257 ]
[192.79166 ]]
'''
# Ask my score
print("Your score will be ", sess.run(hypothesis,
feed_dict={X: [[100, 70, 101]]}))
print("Other scores will be ", sess.run(hypothesis,
feed_dict={X: [[60, 70, 110], [90, 100, 80]]}))Your score will be [[ 181.73277283]]
Other scores will be [[ 145.86265564]
[ 187.23129272]]Queue Runners
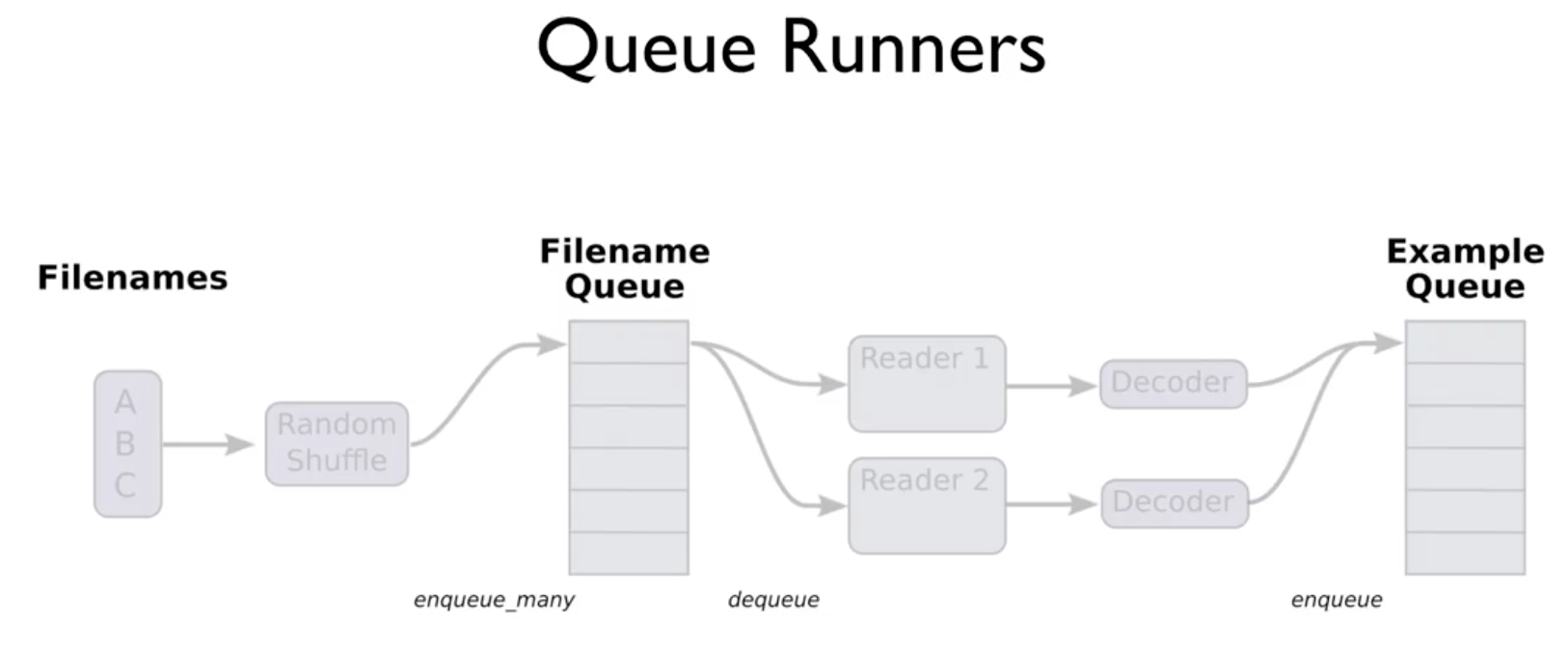
모델을 Train 시켜야 하는 기본 데이터가 많을 때, 이 모든 값들을 메모리에 올려놓고 작업하는 것은 너무 부하가 크다.
그렇기 때문에 Tensorflow는 Queue Runner라는 것을 제공한다. 기본적인 원리는 이렇다.
- 불러와야 할 파일들을 다 가지고 있는다.
- 각각의 파일마다 어떻게 Read할지 정한다. (Reader1, Reader2…)
- 읽어온 파일을 어떻게 Decoding할지 정한다. (Decoder)
- 몇 개씩 학습할지 Batch 단위로 실행한다.
data-01-test-score.csv
73,80,75,152
93,88,93,185
89,91,90,180
96,98,100,196
73,66,70,142
53,46,55,101
69,74,77,149
47,56,60,115
87,79,90,175
79,70,88,164
69,70,73,141
70,65,74,141
93,95,91,184
79,80,73,152
70,73,78,148
93,89,96,192
78,75,68,147
81,90,93,183
88,92,86,177
78,83,77,159
82,86,90,177
86,82,89,175
78,83,85,175
76,83,71,149
96,93,95,192# Lab 4 Multi-variable linear regression
# https://www.tensorflow.org/programmers_guide/reading_data
import tensorflow as tf
tf.set_random_seed(777) # for reproducibility
# Queue Runner를 사용하자.
# filename은 list로 여러개 줄 수 있다.
filename_queue = tf.train.string_input_producer(
['data-01-test-score.csv'], shuffle=False, name='filename_queue')
# filename_queue를 어떻게 read할지 정한다.
# 지금 같은 경우는 text로 읽어오라는 명령을 했다.
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
# 칼럼에 값이 없을 경우 어떤 초기값을 쓸 것인지 정한다.
# Default values, in case of empty columns. Also specifies the type of the
# decoded result.
# 또한 아까 text로 read한 녀석(value)이 어떻게 decoding할 방법을 택한다.
# 지금은 csv 파일을 text로 불러온 뒤 csv 방식으로 해석하라는 명령을 준것이다.
record_defaults = [[0.], [0.], [0.], [0.]]
xy = tf.decode_csv(value, record_defaults=record_defaults)
# batch 라는 단위로 우리는 학습을 할텐데,
# 불러온 데이터를 이 단위로 바꿔줄 필요가 있다.
# decode한 데이터를 X_data, Y_data로 나눠서 batch 함수에 넣도록 하자.
# 그리고 그 결과를 train을 붙인 것에 받자.
# 명심할 것은, 이 작업을 하는 노드를 train_x_batch, train_y_batch라 부르는 것이다.
# 나중에 실행해줘야 이 작업을 실제로 수행한다.
# 한번 펌프질 할때 몇개씩 가져올까? 라는 얘기로 받아들이면 이해가 쉽다.
# collect batches of csv in
train_x_batch, train_y_batch = \
tf.train.batch([xy[0:-1], xy[-1:]], batch_size=10)
# placeholders for a tensor that will be always fed.
X = tf.placeholder(tf.float32, shape=[None, 3])
Y = tf.placeholder(tf.float32, shape=[None, 1])
W = tf.Variable(tf.random_normal([3, 1]), name='weight')
b = tf.Variable(tf.random_normal([1]), name='bias')
# Hypothesis
hypothesis = tf.matmul(X, W) + b
# Simplified cost/loss function
cost = tf.reduce_mean(tf.square(hypothesis - Y))
# Minimize
optimizer = tf.train.GradientDescentOptimizer(learning_rate=1e-5)
train = optimizer.minimize(cost)
# Launch the graph in a session.
sess = tf.Session()
# Initializes global variables in the graph.
sess.run(tf.global_variables_initializer())
# Queue Runner를 사용하기 전에 써주는 코드
# Start populating the filename queue.
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
for step in range(2001):
# 실제 batch를 만들기 위해서 노드를 실행시켜준다.
x_batch, y_batch = sess.run([train_x_batch, train_y_batch])
cost_val, hy_val, _ = sess.run(
[cost, hypothesis, train], feed_dict={X: x_batch, Y: y_batch})
if step % 10 == 0:
print(step, "Cost: ", cost_val, "\nPrediction:\n", hy_val)
# 끝내고 적어주는 코드
coord.request_stop()
coord.join(threads)
# Ask my score
print("Your score will be ",
sess.run(hypothesis, feed_dict={X: [[100, 70, 101]]}))
print("Other scores will be ",
sess.run(hypothesis, feed_dict={X: [[60, 70, 110], [90, 100, 80]]}))...
[172.44307]
[173.06042]
[164.73372]
[158.24258]
[192.79166]]
Your score will be [[181.73277]]
Other scores will be [[145.86266]
[187.2313 ]]