Transformer는 sequence를 순서대로 하나씩 처리하는 대신, sequence 안의 token들이 서로 어떤 관계를 맺는지 attention으로 직접 계산하는 신경망 구조입니다. 2017년 논문 Attention Is All You Need에서 제안되었고, 이후 BERT와 GPT 계열 모델의 기본 뼈대가 되었습니다.
한 문장으로 말하면 Transformer는 각 token이 다른 token을 얼마나 참고해야 하는지를 계산하고, 그 정보를 여러 층으로 쌓아 문맥 표현을 만드는 구조입니다.
왜 필요한가
문장은 순서를 갖습니다. 그래서 과거에는 RNN처럼 앞에서 뒤로 상태를 넘기는 방식이 자연스럽게 쓰였습니다. 하지만 이 방식에는 두 가지 문제가 있습니다.
첫째, 계산이 순차적입니다. 앞 token의 계산이 끝나야 다음 token을 계산할 수 있으므로 긴 문장을 빠르게 병렬 처리하기 어렵습니다.
둘째, 멀리 떨어진 단어 사이의 관계를 배우기 어렵습니다. 앞부분의 정보가 뒤쪽까지 전달되려면 여러 단계를 지나야 하고, 그 과정에서 정보가 약해질 수 있습니다.
Transformer는 이 문제를 self-attention으로 우회합니다. 모든 token이 같은 layer 안에서 서로를 직접 바라볼 수 있게 만들어, 긴 거리의 관계를 짧은 경로로 연결합니다.
기본 구조
원래 논문의 Transformer는 encoder-decoder 구조입니다.
입력 문장
↓
Encoder stack
↓
문맥 표현
↓
Decoder stack
↓
출력 문장Encoder는 입력 sequence를 읽고, decoder는 encoder의 표현을 참고하면서 출력 sequence를 생성합니다. 오늘날의 GPT 계열 모델은 이 중 decoder 쪽 아이디어를 중심으로 변형한 구조에 가깝고, BERT는 encoder 쪽 구조를 중심으로 사용합니다.
그림으로 이해하기
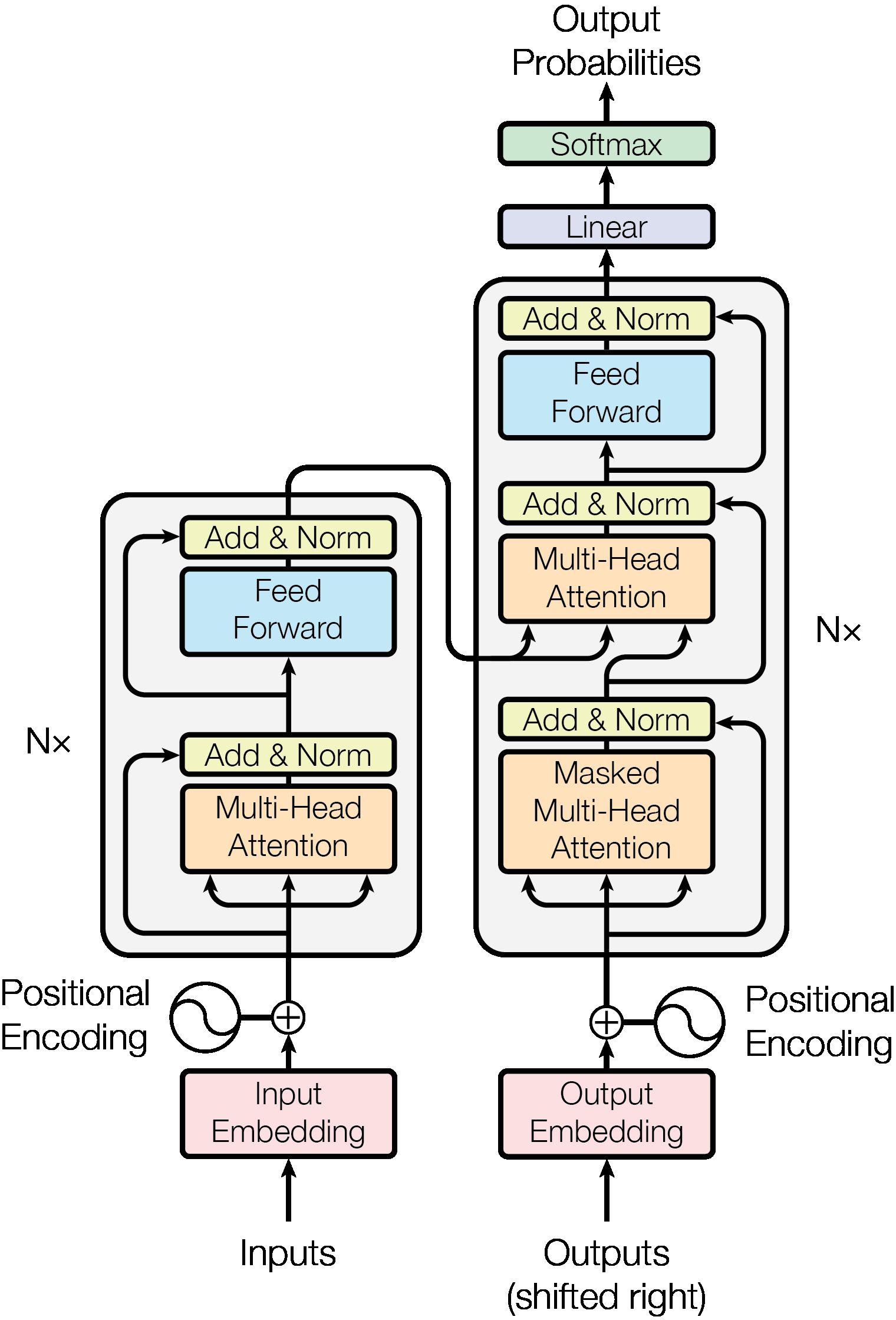
Figure 1. Transformer 전체 구조. 왼쪽은 encoder, 오른쪽은 decoder입니다. 출처: Vaswani et al., Attention Is All You Need.
논문 PDF에서 추출한 Figure 1은 Transformer를 encoder와 decoder 두 덩어리로 나누어 보여줍니다. 왼쪽 encoder는 입력 embedding에 positional encoding을 더한 뒤, 같은 layer를 N번 반복합니다. 각 layer는 multi-head self-attention, Add & Norm, feed-forward network, Add & Norm 순서로 구성됩니다.
오른쪽 decoder는 비슷하지만 attention이 하나 더 있습니다. 먼저 masked multi-head self-attention으로 이전 출력 token들만 참고하고, 그 다음 encoder 출력에 attention을 겁니다. 마지막에는 feed-forward network를 거쳐 linear layer와 softmax가 다음 token 확률을 만듭니다. 이 그림을 보면 Transformer가 단일 attention 블록이 아니라, attention과 feed-forward network를 residual/normalization 구조로 반복해서 쌓은 architecture라는 점이 보입니다.
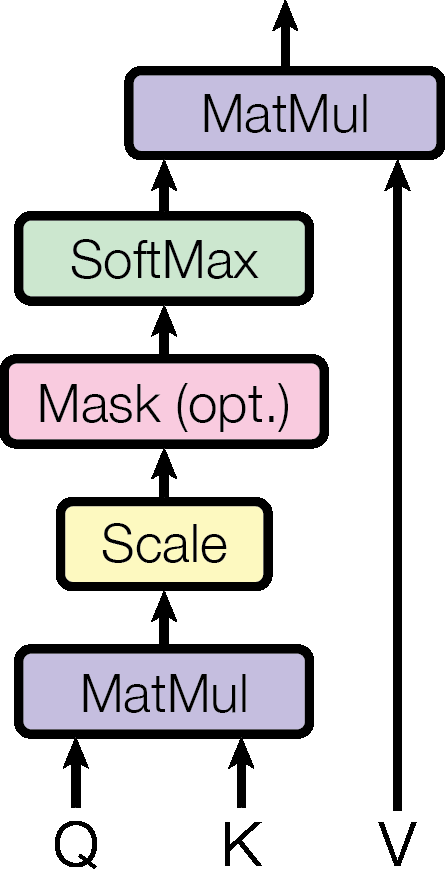
Figure 2 왼쪽. Scaled dot-product attention의 내부 계산 흐름입니다.
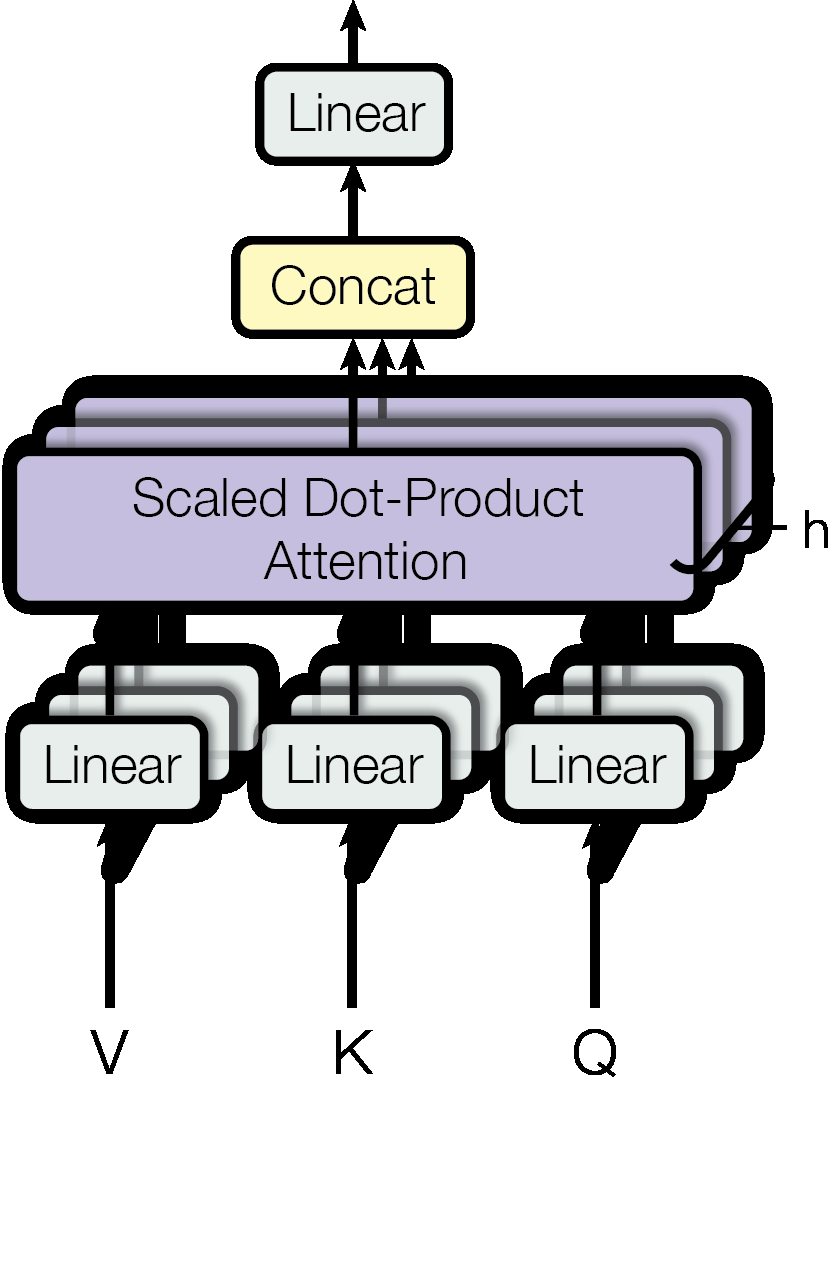
Figure 2 오른쪽. Multi-head attention은 여러 scaled dot-product attention을 병렬로 수행합니다.
Figure 2는 attention 자체를 설명합니다. Scaled dot-product attention은 Q와 K를 행렬 곱으로 비교하고, scale과 optional mask를 적용한 뒤 softmax를 거쳐 V를 섞습니다. Multi-head attention은 이 scaled dot-product attention을 여러 head에서 병렬로 수행하고, 결과를 concat한 뒤 linear layer로 다시 합칩니다. 따라서 multi-head attention은 “attention을 여러 관점에서 동시에 보는 장치”라고 이해할 수 있습니다.
Encoder layer
논문의 encoder layer는 두 부분으로 구성됩니다.
- multi-head self-attention
- position-wise feed-forward network
각 부분 뒤에는 residual connection과 layer normalization이 붙습니다. Residual connection은 입력을 그대로 우회시켜 sub-layer 출력과 더하는 구조이고, layer normalization은 값의 분포를 안정화합니다. 이 조합은 깊은 모델을 학습할 때 gradient와 표현이 불안정해지는 문제를 줄입니다.
Encoder의 self-attention에서는 입력 문장의 각 token이 같은 문장 안의 다른 모든 token을 참고할 수 있습니다.
Decoder layer
Decoder layer는 encoder보다 한 단계가 더 있습니다.
- masked multi-head self-attention
- encoder-decoder attention
- position-wise feed-forward network
Masked self-attention은 미래 token을 보지 못하게 합니다. 예를 들어 번역 결과를 왼쪽에서 오른쪽으로 생성할 때, 아직 생성하지 않은 단어를 보고 다음 단어를 맞히면 안 됩니다.
Encoder-decoder attention은 decoder가 출력 token을 만들 때 encoder의 입력 문장 표현을 참고하는 부분입니다. 번역으로 비유하면, 지금 생성하려는 단어가 원문 문장의 어느 부분을 봐야 하는지 찾는 과정입니다.
Self-attention
Self-attention은 같은 sequence 안에서 token끼리 서로를 참고하는 연산입니다. 각 token은 query, key, value라는 세 종류의 벡터로 변환됩니다.
- Query: 지금 이 token이 찾고 싶은 정보
- Key: 다른 token들이 가진 식별 정보
- Value: 실제로 가져올 내용
Query와 key의 유사도를 계산하면 “이 token이 저 token을 얼마나 참고해야 하는가”라는 점수가 나옵니다. 이 점수에 softmax를 적용해 가중치로 만들고, value를 가중합하면 attention 결과가 됩니다.
Scaled dot-product attention
논문에서 사용한 attention은 scaled dot-product attention입니다. Query와 key의 내적을 계산한 뒤, key 차원의 제곱근으로 나눕니다. 그 다음 softmax를 통과시켜 value에 곱합니다.
scale을 넣는 이유는 차원이 커질수록 내적 값이 커져 softmax가 너무 뾰족해질 수 있기 때문입니다. softmax가 지나치게 한쪽으로 쏠리면 gradient가 작아지고 학습이 어려워질 수 있습니다.
Multi-head attention
Multi-head attention은 attention을 여러 번 병렬로 수행하는 방식입니다. 하나의 큰 attention을 한 번 계산하는 대신, query/key/value를 여러 개의 작은 공간으로 나누어 각각 attention을 계산한 뒤 다시 합칩니다.
이렇게 하면 모델은 여러 관점의 관계를 동시에 볼 수 있습니다.
- 어떤 head는 가까운 단어 관계를 볼 수 있습니다.
- 어떤 head는 멀리 떨어진 의존성을 볼 수 있습니다.
- 어떤 head는 대명사가 가리키는 대상을 볼 수 있습니다.
- 어떤 head는 문법적 역할을 포착할 수 있습니다.
논문은 attention visualization에서 일부 head가 “making … more difficult”처럼 멀리 떨어진 표현을 연결하거나, “its”가 가리키는 대상을 날카롭게 보는 모습을 보여줍니다.
Positional encoding
Self-attention은 순서 정보를 직접 갖고 있지 않습니다. “나는 학교에 갔다”와 “학교가 나에게 왔다”는 단어 집합이 비슷해도 순서가 다르면 의미가 다릅니다. 따라서 Transformer는 token embedding에 positional encoding을 더합니다.
원 논문은 sine/cosine 함수를 이용한 고정 positional encoding을 사용했습니다. 위치마다 서로 다른 주기의 값을 넣으면 모델이 token의 위치와 상대적 거리 정보를 활용할 수 있습니다.
중요한 점은 Transformer가 순서를 버린 것이 아니라, 순서 처리를 recurrence에 맡기지 않고 별도 위치 정보로 주입했다는 것입니다.
Feed-forward network
각 attention layer 뒤에는 position-wise feed-forward network가 있습니다. 이는 각 token 위치에 독립적으로 적용되는 작은 MLP입니다. Attention이 token 사이의 정보를 섞는 역할을 한다면, feed-forward network는 각 위치의 표현을 비선형적으로 변환해 더 풍부한 특징을 만듭니다.
원 논문 base 모델에서는 d_model = 512, feed-forward 내부 차원은 d_ff = 2048을 사용했습니다.
왜 확장에 유리했나
Transformer가 중요해진 이유는 성능만이 아닙니다. 구조적으로 병렬화에 유리했기 때문입니다.
RNN은 sequence 길이 방향으로 계산이 이어지지만, Transformer의 self-attention은 한 layer 안에서 여러 위치를 동시에 계산할 수 있습니다. 이것은 GPU/TPU 같은 병렬 하드웨어와 잘 맞습니다. 모델과 데이터가 커질수록 이 차이는 매우 중요해집니다.
또한 token 사이의 path length가 짧습니다. RNN에서는 멀리 떨어진 두 token이 여러 recurrent step을 거쳐 연결되지만, self-attention에서는 한 layer 안에서 직접 연결될 수 있습니다. 이 특성은 긴 문맥의 의존성을 학습하는 데 유리합니다.
한계
Transformer에도 한계가 있습니다. 가장 대표적인 것은 attention의 계산량입니다. 모든 token 쌍을 비교하므로 sequence 길이 n에 대해 self-attention 비용은 대략 n²에 비례합니다. 짧거나 중간 길이의 문장에서는 강력하지만, 매우 긴 문서나 고해상도 이미지, 긴 오디오를 그대로 처리할 때는 비용이 커집니다.
그래서 이후 연구에서는 sparse attention, local attention, linear attention, retrieval, chunking, long-context architecture 같은 다양한 변형이 등장했습니다.
헷갈리지 말아야 할 점
Transformer는 “attention만 있으면 된다”는 말로 단순화하면 오해가 생깁니다. 실제 구조는 attention, positional encoding, residual connection, layer normalization, feed-forward network, masking, optimizer와 regularization 선택이 함께 작동합니다.
또한 현재의 LLM이 모두 논문 원형의 encoder-decoder Transformer라는 뜻도 아닙니다. GPT 계열은 decoder-only 구조를 사용하고, BERT 계열은 encoder 중심 구조를 사용합니다. 그러나 두 흐름 모두 이 논문이 정리한 self-attention 기반 architecture에서 출발했습니다.