Attention Is All You Need는 2017년에 발표된 Transformer 논문입니다. 제목 그대로, 이 논문은 기계 번역 같은 sequence transduction 문제에서 recurrent layer나 convolutional layer를 쓰지 않고도 attention만으로 강한 모델을 만들 수 있다고 주장했습니다.
논문의 의미는 “attention이라는 부품을 하나 더 붙였다”가 아닙니다. 이전에도 encoder-decoder 구조와 attention은 이미 쓰이고 있었습니다. 이 논문의 핵심은 순차적으로 정보를 넘기는 RNN/CNN 중심 구조를 빼고, self-attention과 feed-forward network를 쌓은 구조만으로 encoder-decoder 모델을 구성했다는 점입니다. 이 선택이 병렬 학습, 긴 의존성 처리, 모델 확장성 측면에서 큰 변화를 만들었습니다.
배경: 왜 RNN을 빼려고 했나
논문이 문제 삼은 것은 당시 sequence model의 순차성입니다. RNN, LSTM, GRU 계열 모델은 입력 token을 순서대로 처리하면서 hidden state를 갱신합니다. 이 방식은 문장의 순서를 자연스럽게 다루지만, 훈련할 때 한 문장 안의 위치들을 완전히 병렬로 처리하기 어렵습니다.
긴 문장에서 앞부분의 정보가 뒤쪽 token까지 전달되려면 여러 계산 단계를 지나야 합니다. 논문은 이것을 long-range dependency를 학습하기 어렵게 만드는 요인 중 하나로 봅니다. 계산이 순차적이면 GPU를 써도 한 training example 내부의 병렬화가 제한되고, 길이가 길어질수록 학습 효율도 떨어집니다.
Transformer는 이 병목을 줄이기 위해 각 위치가 다른 모든 위치를 직접 참고할 수 있는 self-attention을 중심 연산으로 둡니다. 덕분에 한 layer 안에서 두 token 사이의 경로 길이가 짧아지고, sequence의 여러 위치를 동시에 계산하기 쉬워집니다.
모델 구조
논문은 일반적인 encoder-decoder 구조를 유지합니다. Encoder는 입력 sequence를 연속 표현으로 바꾸고, decoder는 그 표현을 참고해 출력 sequence를 하나씩 생성합니다. 다른 점은 encoder와 decoder 내부를 구성하는 방식입니다.
Encoder
Encoder는 6개의 동일한 layer를 쌓아 만듭니다. 각 layer에는 두 개의 sub-layer가 있습니다.
- multi-head self-attention
- position-wise feed-forward network
각 sub-layer 주변에는 residual connection이 있고, 그 뒤에 layer normalization이 붙습니다. 즉 정보가 sub-layer를 통과한 결과와 원래 입력을 더한 뒤 정규화합니다. 이 구조는 깊은 네트워크를 안정적으로 학습시키기 위한 장치입니다.
Decoder
Decoder도 6개의 layer를 쌓지만, encoder보다 sub-layer가 하나 더 많습니다.
- masked multi-head self-attention
- encoder 출력에 attention을 거는 multi-head attention
- position-wise feed-forward network
첫 번째 attention에 mask를 쓰는 이유는 번역 결과를 생성할 때 아직 생성하지 않은 미래 token을 보면 안 되기 때문입니다. Decoder는 이전에 생성한 token만 보고 다음 token을 예측해야 하므로, 오른쪽 방향의 정보를 가립니다.
논문 그림으로 보는 구조
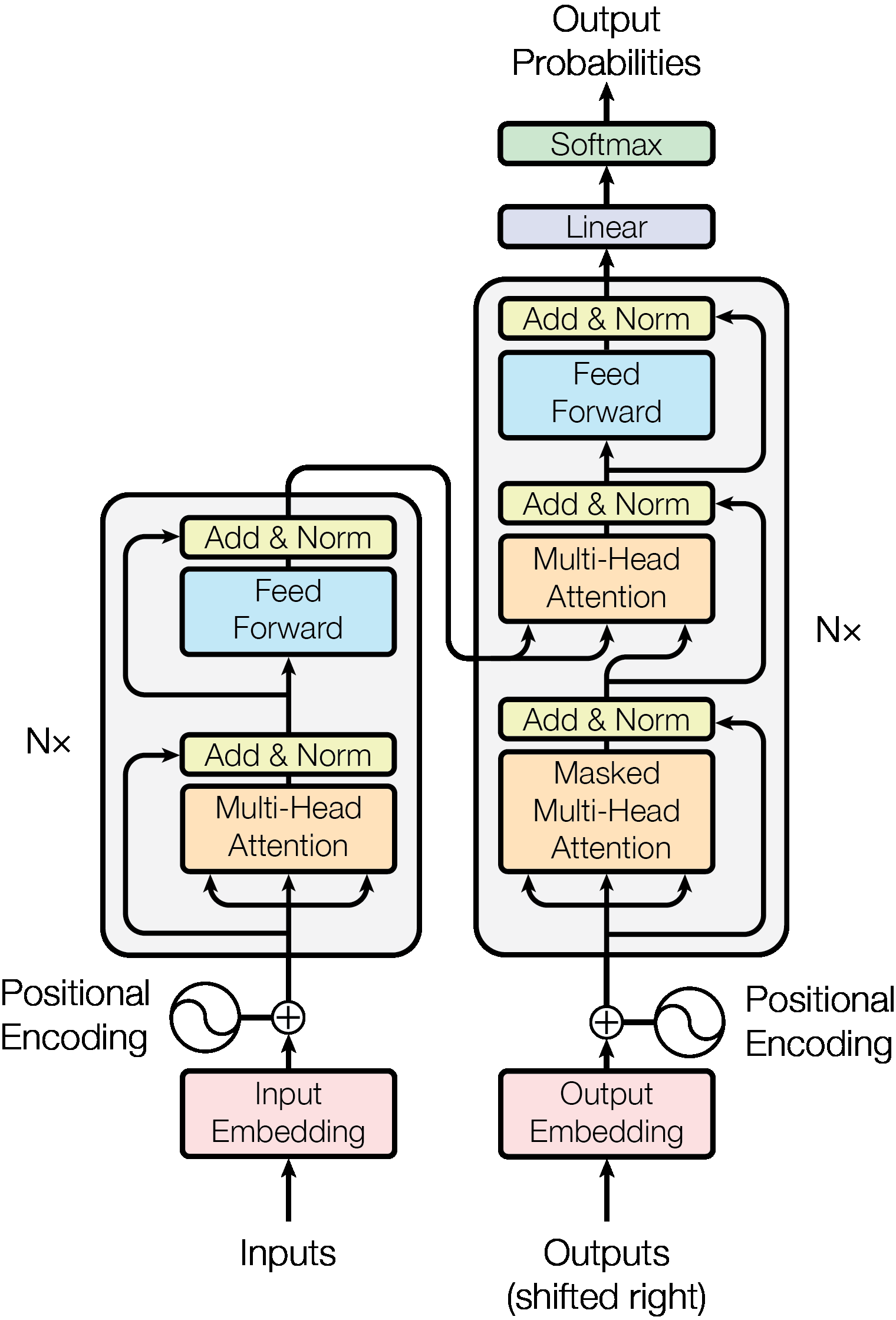
Figure 1. Transformer 전체 구조. 출처: Vaswani et al., Attention Is All You Need.
PDF에서 추출한 Figure 1은 Transformer 전체 구조를 한 장으로 보여줍니다. 왼쪽은 encoder, 오른쪽은 decoder입니다. 입력 token은 embedding으로 바뀐 뒤 positional encoding이 더해지고, encoder stack을 통과합니다. Encoder layer 안에는 multi-head attention과 feed-forward network가 있으며, 각 sub-layer 뒤에는 Add & Norm이 붙어 있습니다.
오른쪽 decoder는 output embedding에 positional encoding을 더한 뒤 시작합니다. Decoder의 첫 attention은 masked multi-head attention입니다. 이는 아직 생성하지 않은 미래 token을 보지 못하게 막습니다. 그 다음 decoder는 encoder 출력에 다시 attention을 걸고, feed-forward network를 거친 뒤 linear layer와 softmax를 통해 다음 token의 확률을 만듭니다.
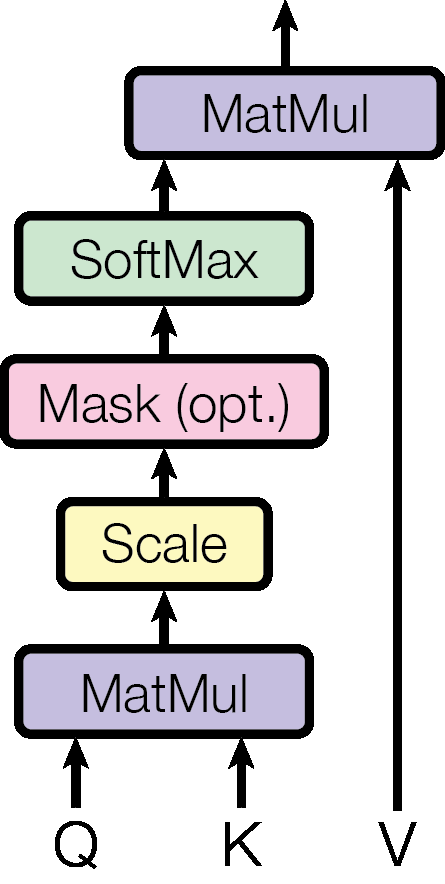
Figure 2 왼쪽. Scaled dot-product attention. Q와 K의 관계를 점수화하고, mask와 softmax를 거쳐 V를 가중합합니다.
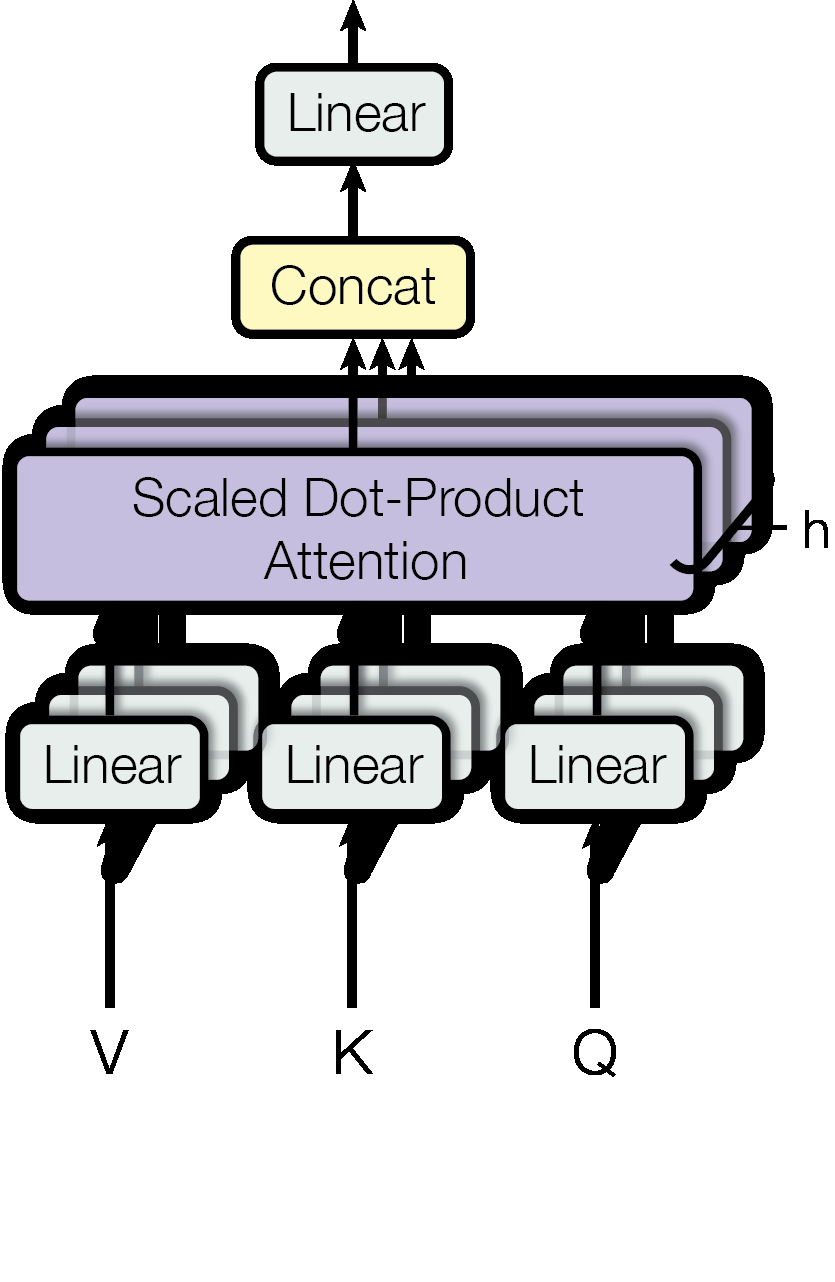
Figure 2 오른쪽. Multi-head attention. 여러 attention head를 병렬로 계산한 뒤 concat하고 linear layer로 다시 합칩니다.
Figure 2는 attention 내부를 더 작게 나누어 보여줍니다. Scaled dot-product attention은 Q와 K를 곱하고, scale을 적용한 뒤, 필요하면 mask를 씌우고, softmax를 거쳐 V를 가중합합니다. Multi-head attention은 이 과정을 여러 head에서 병렬로 수행한 뒤 concat하고 linear layer를 통과시킵니다. 이 그림 덕분에 “attention”이 하나의 추상적 아이디어가 아니라, 실제로는 행렬 곱, scaling, masking, softmax, value 조합으로 이루어진 계산이라는 점이 분명해집니다.
Attention 계산
논문은 attention을 query, key, value의 관계로 설명합니다. Query는 “무엇을 찾고 싶은가”, key는 “각 항목이 어떤 특징을 갖는가”, value는 “실제로 가져올 정보”에 가깝습니다.
Scaled dot-product attention은 query와 key의 내적을 계산해 관련도를 구하고, 이를 key 차원의 제곱근으로 나누어 scale을 맞춘 뒤 softmax를 적용합니다. 마지막으로 이 가중치를 value에 곱해 합칩니다.
간단히 말하면, 각 token이 문장 안의 다른 token들을 얼마나 참고할지 점수화하고, 그 점수에 따라 정보를 섞는 과정입니다.
Multi-head attention
하나의 attention만 쓰면 token 사이의 관계를 한 가지 관점으로만 보게 됩니다. 논문은 query, key, value를 여러 개의 낮은 차원 공간으로 선형 변환한 뒤, 각 공간에서 attention을 병렬로 계산합니다. 이것이 multi-head attention입니다.
여러 head는 서로 다른 종류의 관계를 볼 수 있습니다. 어떤 head는 문법적 연결을, 어떤 head는 먼 거리의 의존성을, 어떤 head는 특정 단어 주변의 지역적 패턴을 더 잘 볼 수 있습니다. 논문 후반의 attention visualization은 실제로 일부 head가 긴 거리의 동사구 관계나 대명사 참조에 반응하는 모습을 보여줍니다.
위치 정보는 어떻게 넣나
Self-attention 자체는 입력의 순서를 알지 못합니다. token들이 한꺼번에 들어오면, attention은 어느 token이 앞에 있었고 뒤에 있었는지 자동으로 알 수 없습니다.
그래서 Transformer는 embedding에 positional encoding을 더합니다. 논문은 sine과 cosine 함수를 이용한 고정 positional encoding을 사용합니다. 서로 다른 주기의 sin/cos 값을 각 위치에 부여하면, 모델은 token의 절대 위치뿐 아니라 상대적 위치 관계도 학습할 수 있습니다. 논문은 학습 가능한 positional embedding도 실험했고, 성능은 비슷했다고 보고합니다.
왜 self-attention인가
논문은 self-attention을 recurrent layer, convolutional layer와 비교할 때 세 가지 기준을 봅니다.
- layer당 계산 복잡도
- 병렬화 가능한 정도
- 먼 위치 사이의 path length
Self-attention은 sequence 길이가 representation 차원보다 짧은 경우 계산량 측면에서 유리하고, 모든 위치를 동시에 계산할 수 있어 병렬화에 강합니다. 또한 한 layer 안에서 임의의 두 위치가 직접 연결될 수 있으므로 long-range dependency의 경로가 짧습니다.
물론 self-attention은 모든 token 쌍을 비교하므로 sequence 길이가 매우 길어지면 비용이 커집니다. 논문도 결론에서 이미지, 오디오, 비디오처럼 큰 입력을 다루기 위해 local/restricted attention을 탐구하겠다고 말합니다.
학습과 실험 결과
논문은 WMT 2014 English-to-German, English-to-French 번역 태스크에서 모델을 평가했습니다. Base 모델은 8개의 NVIDIA P100 GPU를 사용해 약 12시간 동안 100,000 step 학습했고, Big 모델은 약 3.5일 동안 300,000 step 학습했습니다.
결과는 당시 기준으로 강했습니다.
- English-to-German: Transformer big이 BLEU 28.4를 기록해 기존 최고 결과를 2 BLEU 이상 넘었습니다.
- English-to-French: Transformer big이 BLEU 41.8을 기록했습니다.
- 특히 English-to-German에서는 기존 ensemble 모델들보다도 높은 성능을 보였습니다.
중요한 점은 성능만이 아니라 훈련 비용입니다. 논문은 Transformer가 이전의 강한 모델들보다 훨씬 적은 training cost로 경쟁력 있는 결과를 냈다고 강조합니다.
논문이 바꾼 관점
이 논문 이후 sequence model을 생각하는 기본 관점이 달라졌습니다. 이전에는 순서를 다루려면 순차적인 recurrence가 자연스럽다고 여겨졌습니다. Transformer는 순서를 별도 positional information으로 주고, token 사이의 관계는 attention으로 직접 계산하는 방식도 충분히 강하다는 것을 보여주었습니다.
이 아이디어는 이후 BERT, GPT 계열 모델의 기반이 되었습니다. 물론 현대 LLM은 이 논문의 원형 Transformer와 완전히 같지는 않습니다. decoder-only 구조, pretraining objective, scaling law, instruction tuning 등 많은 변화가 더해졌습니다. 그래도 “attention 중심의 병렬화 가능한 sequence model”이라는 기본 전환점은 이 논문에서 시작됐다고 볼 수 있습니다.
헷갈리지 말아야 할 점
Transformer는 단순히 attention 하나를 쓴 모델이 아닙니다. Multi-head attention, feed-forward network, residual connection, layer normalization, positional encoding, masking, encoder-decoder attention이 함께 설계된 구조입니다.
또한 이 논문은 처음부터 범용 대형 언어 모델을 제안한 논문이라기보다는, 기계 번역을 중심으로 sequence transduction 모델을 새롭게 구성한 논문입니다. 이후 이 구조가 언어 모델링과 대규모 사전학습에 확장되면서 오늘날의 LLM 흐름으로 이어졌습니다.
출처
- arXiv: 1706.03762
- PDF: https://arxiv.org/pdf/1706.03762